20 awk examples
Many utility tools exist in the Linux operating system to search and generate a report from text data or file. The user can easily perform many types of searching, replacing and report generating tasks by using awk, grep and sed commands. awk is not just a command. It is a scripting language that can be used from both terminal and awk file. It supports the variable, conditional statement, array, loops etc. like other scripting languages. It can read any file content line by line and separate the fields or columns based on a specific delimiter. It also supports regular expression for searching particular string in the text content or file and takes actions if any match founds. How you can use awk command and script is shown in this tutorial by using 20 useful examples.
Contents:
- awk with printf
- awk to split on white space
- awk to change the delimiter
- awk with tab-delimited data
- awk with csv data
- awk regex
- awk case insensitive regex
- awk with nf (number of fields) variable
- awk gensub() function
- awk with rand() function
- awk user defined function
- awk if
- awk variables
- awk arrays
- awk loop
- awk to print the first column
- awk to print the last column
- awk with grep
- awk with the bash script file
- awk with sed
Using awk with printf
printf() function is used to format any output in most of the programming languages. This function can be used with awk command to generate different types of formatted outputs. awk command mainly used for any text file. Create a text file named employee.txt with the content given below where fields are separated by tab (‘t’).
employee.txt
1002 Jafar Iqbal 60000
1003 Meher Nigar 30000
1004 Jonny Liver 70000
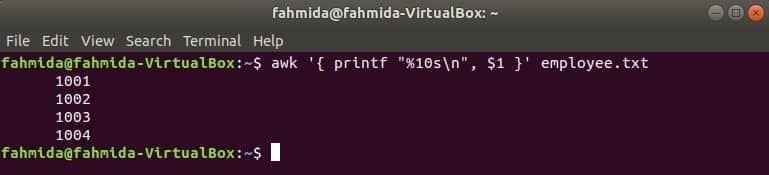
The following awk command will read data from employee.txt file line by line and print the first filed after formatting. Here, “%10sn” means that the output will be 10 characters long. If the value of the output is less than 10 characters then the spaces will be added at the front of the value.
Output:
awk to split on white space
The default word or field separator for splitting any text is white space. awk command can take text value as input in various ways. The input text is passed from echo command in the following example. The text, ‘I like programming’ will be split by default separator, space, and the third word will be printed as output.
Output:

awk to change the delimiter
awk command can be used to change the delimiter for any file content. Suppose, you have a text file named phone.txt with the following content where ‘:’ is used as field separator of the file content.
phone.txt
+880:1855:456:907
+9:7777:38644:808
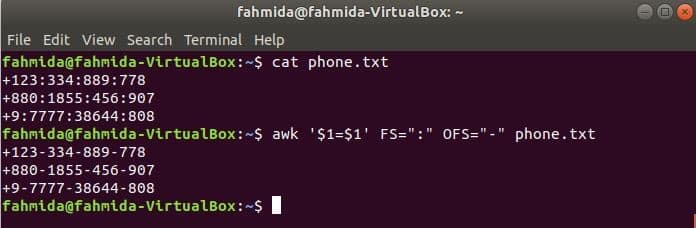
Run the following awk command to change the delimiter, ‘:’ by ‘-’ to the content of the file, phone.txt.
$ awk ‘$1=$1’ FS=":" OFS="-" phone.txt
Output:
awk with tab-delimited data
awk command has many built-in variables which are used to read the text in different ways. Two of them are FS and OFS. FS is input field separator and OFS is output field separator variables. The uses of these variables are shown in this section. Create a tab separated file named input.txt with the following content to test the uses of FS and OFS variables.
Input.txt
Server-side scripting language
Database Server
Web Server
Using FS variable with tab
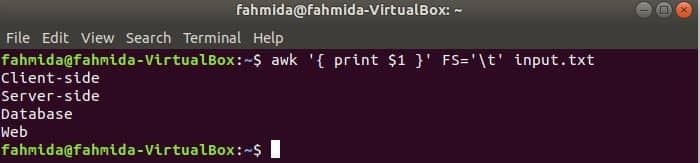
The following command will split each line of input.txt file based on the tab (‘t’) and print the first field of each line.
Output:
Using OFS variable with tab
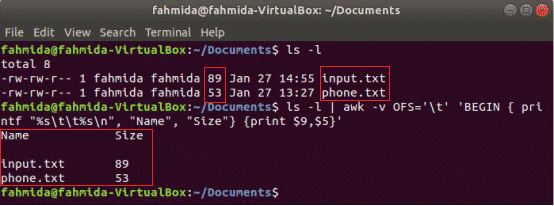
The following awk command will print the 9th and 5th fields of ‘ls -l’ command output with tab separator after printing the column title “Name” and “Size”. Here, OFS variable is used to format the output by a tab.
$ ls -l | awk -v OFS=‘t’ ‘BEGIN { printf "%st%sn", "Name", "Size"} {print $9,$5}’
Output:
awk with CSV data
The content of any CSV file can be parsed in multiple ways by using awk command. Create a CSV file named ‘customer.csv’ with the following content to apply awk command.
customer.txt
1, Sophia, [email protected], (862) 478-7263
2, Amelia, [email protected], (530) 764-8000
3, Emma, [email protected], (542) 986-2390
Reading single field of CSV file
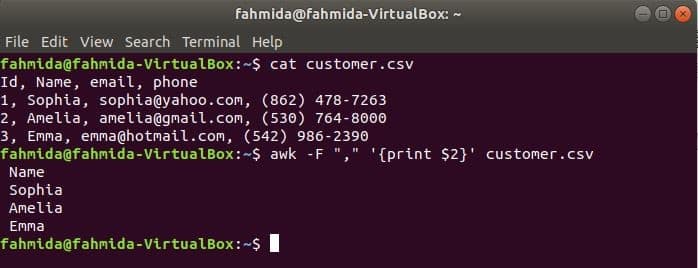
‘-F’ option is used with awk command to set the delimiter for splitting each line of the file. The following awk command will print the name field of the customer.csv file.
$ awk -F "," ‘{print $2}’ customer.csv
Output:
Reading multiple fields by combining with other text
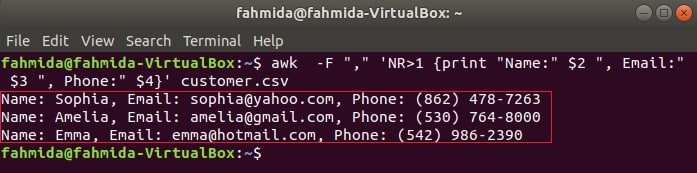
The following command will print three fields of customer.csv by combining title text, Name, Email, and Phone. The first line of the customer.csv file contains the title of each field. NR variable contains the line number of the file when awk command parses the file. In this example, the NR variable is used to omit the first line of the file. The output will show the 2nd, 3rd and 4th fields of all lines except the first line.
Output:
Reading CSV file using an awk script
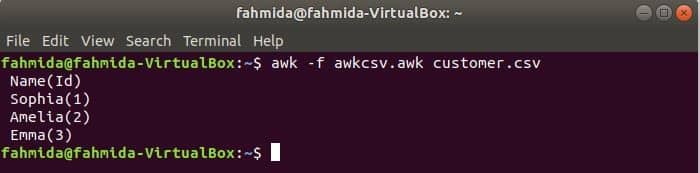
awk script can be executed by running awk file. How you can create awk file and run the file is shown in this example. Create a file named awkcsv.awk with the following code. BEGIN keyword is used in the script for informing awk command to execute the script of the BEGIN part first before executing other tasks. Here, field separator (FS) is used to define splitting delimiter and 2nd and 1st fields will be printed according to the format used in printf() function.
Run awkcsv.awk file with the content of the customer.csv file by the following command.
Output:
awk regex
The regular expression is a pattern that is used to search any string in a text. Different types of complicated search and replace tasks can be done very easily by using the regular expression. Some simple uses of the regular expression with awk command are shown in this section.
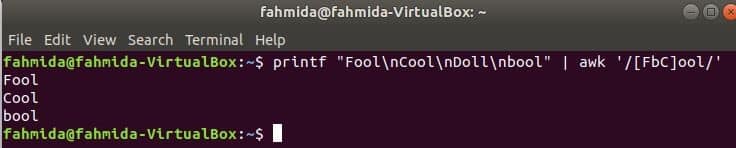
The following command will match the word Fool or bool or Cool with the input string and print if the word founds. Here, Doll will not match and not print.
Output:
Searching string at the start of the line
‘^’ symbol is used in the regular expression to search any pattern at the starting of the line. ‘Linux’ word will be searched at the starting of each line of the text in the following example. Here, two lines start with the text, ‘Linux’ and those two lines will be shown in the output.
a popular blog site" | awk ‘/^Linux/’
Output:
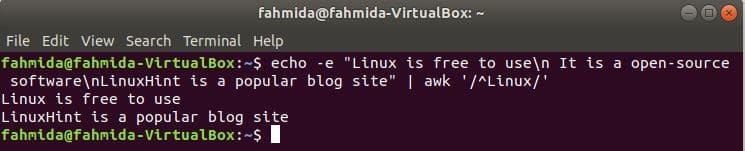
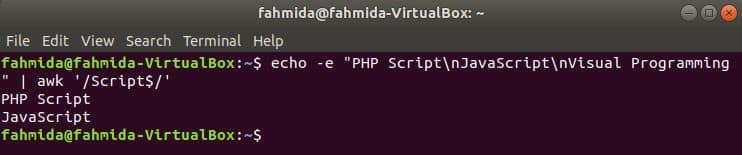
Searching string at the end of the line
‘$’ symbol is used in the regular expression to search any pattern at the end of each line of the text. ‘Script’ word is searched in the following example. Here, two lines contain the word, Script at the end of the line.
Output:
Searching by omitting particular character set
‘^’ symbol indicates the starting of the text when it is used in front of any string pattern (‘/^…/’) or before any character set declared by ^[…]. If the ‘^’ symbol is used inside the third bracket, [^…] then the defined character set inside the bracket will be omitted at the time of searching. The following command will search any word that is not starting with ‘F’ but ending with ‘ool’. Cool and bool will be printed according to the pattern and text data.
Output:

awk case insensitive regex
By default, regular expression does case sensitive search when searching any pattern in the string. Case insensitive search can be done by awk command with the regular expression. In the following example, tolower() function is used to do case insensitive search. Here, the first word of each line of the input text will be converted to lower case by using tolower() function and match with the regular expression pattern. toupper() function can also be used for this purpose, in this case, the pattern must be defined by all capital letter. The text defined in the following example contains the searching word, ‘web’ in two lines which will be printed as output.
Output:
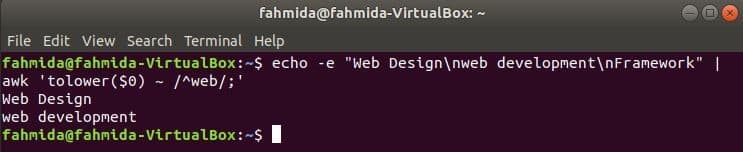
awk with NF (number of fields) variable
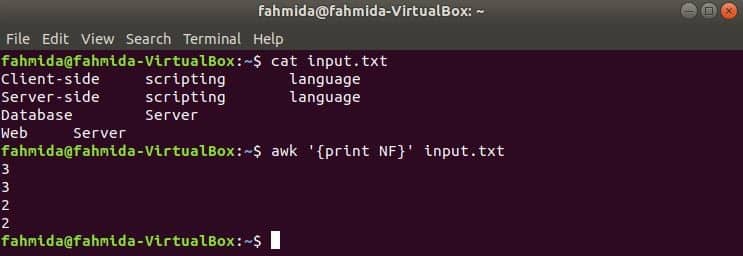
NF is a built-in variable of awk command which is used to count the total number of fields in each line of the input text. Create any text file with multiple lines and multiple words. the input.txt file is used here which is created in the previous example.
Using NF from the command line
Here, the first command is used to display the content of input.txt file and second command is used to show the total number of fields in each line of the file using NF variable.
$ awk ‘{print NF}’ input.txt
Output:
Using NF in awk file
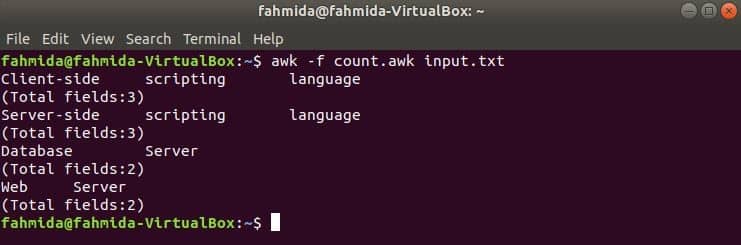
Create an awk file named count.awk with the script given below. When this script will execute with any text data then each line content with total fields will be printed as output.
count.awk
{print "[Total fields:" NF "]"}
Run the script by the following command.
Output:
awk gensub() function
getsub() is a substitution function that is used to search string based on particular delimiter or regular expression pattern. This function is defined in ‘gawk’ package which is not installed by default. The syntax for this function is given below. The first parameter contains the regular expression pattern or searching delimiter, the Second parameter contains the replacement text, the third parameter indicates how the search will be done and the last parameter contains the text in which this function will be applied.
Syntax:
Run the following command to install gawk package for using getsub() function with awk command.
Create a text file named ‘salesinfo.txt’ with the following content to practice this example. Here, the fields are separated by a tab.
salesinfo.txt
Tue 800000
Wed 750000
Thu 200000
Fri 430000
Sat 820000
Run the following command to read the numeric fields of the salesinfo.txt file and print the total of all sales amount. Here, the third parameter, ‘G’ indicates the global search. That means the pattern will be searched in the full content of the file.
Output:

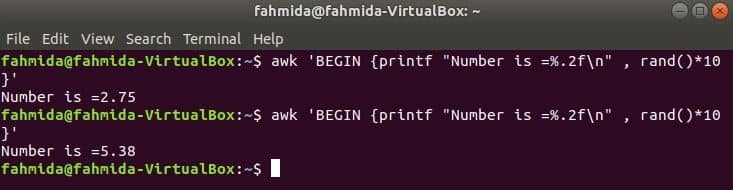
awk with rand() function
rand() function is used to generate any random number greater than 0 and less than 1. So, it will always generate a fractional number less than 1. The following command will generate a fractional random number and multiply the value with 10 to get a number more than 1. A fractional number with two digits after the decimal point will be printed for applying printf() function. If you run the following command multiple times then you will get different output every time.
Output:
awk user defined function
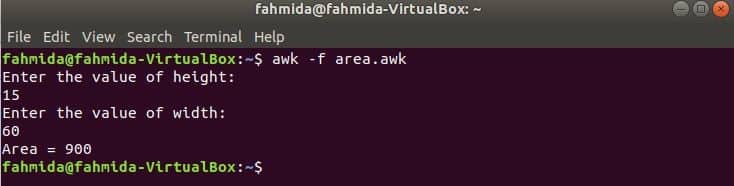
All functions which are used in the previous examples are built-in functions. But you can declare a user-defined function in your awk script to do any particular task. Suppose, you want to create a custom function to calculate the area of a rectangle. To do this task, create a file named ‘area.awk’ with the following script. In this example, a user-defined function named area() is declared in the script that calculates the area based on the input parameters and returns the area value. getline command is used here to take input from the user.
area.awk
function area(height,width){
return height*width
}
# Starts execution
BEGIN {
print "Enter the value of height:"
getline h < "-"
print "Enter the value of width:"
getline w < "-"
print "Area = " area(h,w)
}
Run the script.
Output:
awk if example
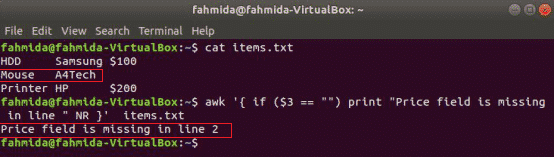
awk supports conditional statements like other standard programming languages. Three types of if statements are shown in this section by using three examples. Create a text file named items.txt with the following content.
items.txt
Mouse A4Tech
Printer HP $200
Simple if example:
he following command will read the content of the items.txt file and check the 3rd field value in each line. If the value is empty then it will print an error message with the line number.
Output:
if-else example:
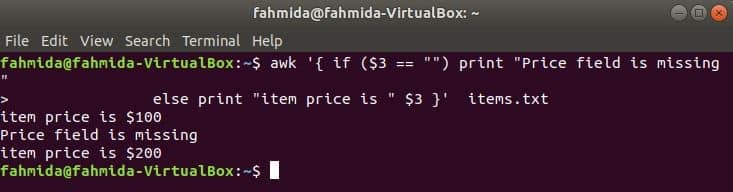
The following command will print the item price if the 3rd field exists in the line, otherwise, it will print an error message.
else print "item price is " $3 }’ items.txt
Output:
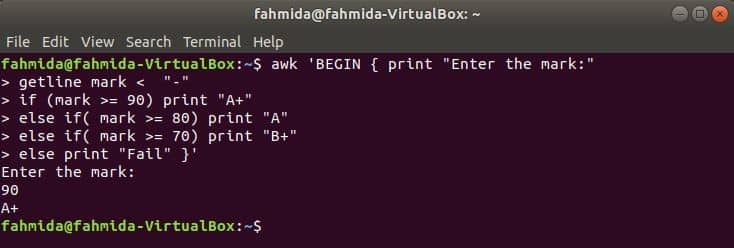
if-else-if example:
When the following command will execute from the terminal then it will take input from the user. The input value will be compared with each if condition until the condition is true. If any condition becomes true then it will print the corresponding grade. If the input value does not match with any condition then it will print fail.
getline mark < "-"
if (mark >= 90) print "A+"
else if( mark >= 80) print "A"
else if( mark >= 70) print "B+"
else print "Fail" }’
Output:
awk variables
The declaration of awk variable is similar to the declaration of the shell variable. There is a difference in reading the value of the variable. ‘$’ symbol is used with the variable name for the shell variable to read the value. But there is no need to use ‘$’ with awk variable to read the value.
Using simple variable:
The following command will declare a variable named ‘site’ and a string value is assigned to that variable. The value of the variable is printed in the next statement.
Output:

Using a variable to retrieve data from a file
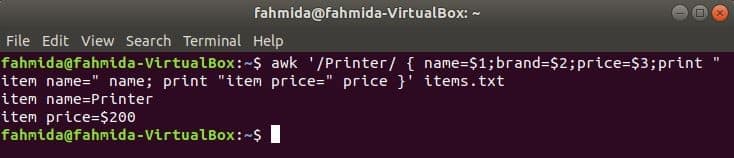
The following command will search the word ‘Printer’ in the file items.txt. If any line of the file starts with ‘Printer’ then it will store the value of 1st, 2nd and 3rd fields into three variables. name and price variables will be printed.
print "item price=" price }’ items.txt
Output:
awk arrays
Both numeric and associated arrays can be used in awk. Array variable declaration in awk is same to other programming languages. Some uses of arrays are shown in this section.
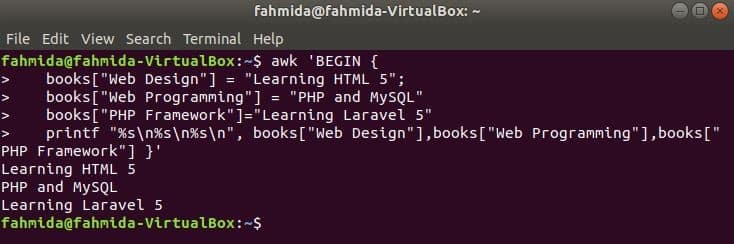
Associative Array:
The index of the array will be any string for the associative array. In this example, an associative array of three elements are declared and printed.
books["Web Design"] = "Learning HTML 5";
books["Web Programming"] = "PHP and MySQL"
books["PHP Framework"]="Learning Laravel 5"
printf "%sn%sn%sn", books["Web Design"],books["Web Programming"],
books["PHP Framework"] }’
Output:
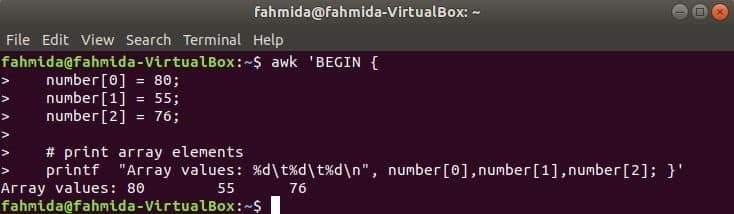
Numeric Array:
A numeric array of three elements are declared and printed by separating tab.
number[0] = 80;
number[1] = 55;
number[2] = 76;
 
# print array elements
printf "Array values: %dt%dt%dn", number[0],number[1],number[2]; }’
Output:
awk loop
Three types of loops are supported by awk. The uses of these loops are shown here by using three examples.
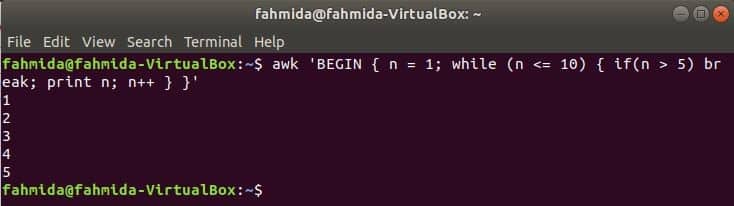
While loop:
while loop that is used in the following command will iterate for 5 times and exit from the loop for break statement.
Output:
For loop:
For loop that is used in the following awk command will calculate the sum from 1 to 10 and print the value.
Output:

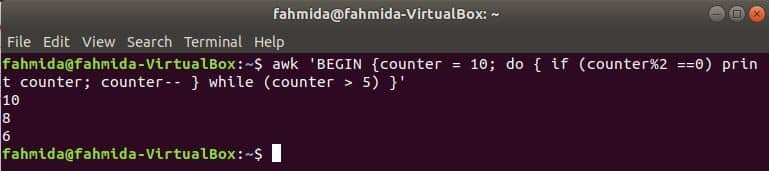
Do-while loop:
a do-while loop of the following command will print all even numbers from 10 to 5.
while (counter > 5) }’
Output:
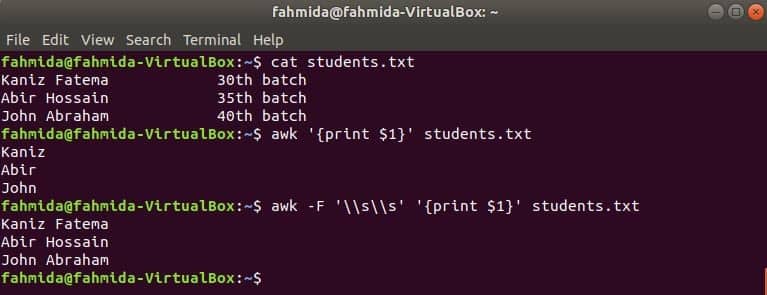
awk to print the first column
The first column of any file can be printed by using $1 variable in awk. But if the value of the first column contains multiple words then only the first word of the first column prints. By using a specific delimiter, the first column can be printed properly. Create a text file named students.txt with the following content. Here, the first column contains the text of two words.
Students.txt
Abir Hossain 35<sup>th</sup> batch
John Abraham 40<sup>th</sup> batch
Run awk command without any delimiter. The first part of the first column will be printed.
Run awk command with the following delimiter. The full part of the first column will be printed.
Output:
awk to print the last column
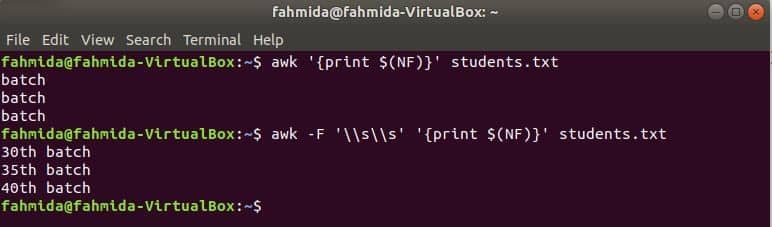
$(NF) variable can be used to print the last column of any file. The following awk commands will print the last part and full part of the last column of the students.txt file.
$ awk -F ‘\s\s’ ‘{print $(NF)}’ students.txt
Output:
awk with grep
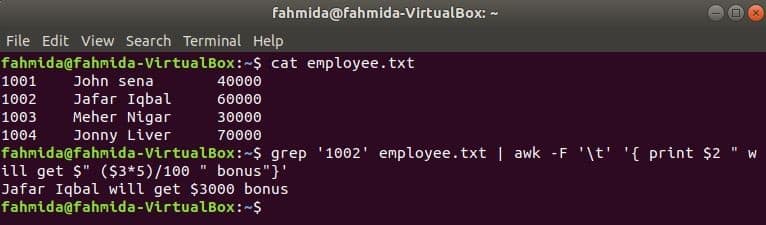
grep is another useful command of Linux to search content in a file based on any regular expression. How both awk and grep commands can be used together is shown in the following example. grep command is used to search information of the employee id, ‘1002’ from the employee.txt file. The output of the grep command will be sent to awk as input data. 5% bonus will be counted and printed based on the salary of the employee id, ‘1002’ by awk command.
$ grep ‘1002’ employee.txt | awk -F ‘t’ ‘{ print $2 " will get $" ($3*5)/100 " bonus"}’
Output:
awk with BASH file
Like other Linux command, awk command can also be used in a BASH script. Create a text file named customers.txt with the following content. Each line of this file contains information on four fields. These are customer’s ID, Name, address and mobile number those are separated by ‘/’.
customers.txt
CA5455 / Virginia S Mota / 930 Bassel Street,VALLECITO,California / 415-679-5908
IL4855 / Ann A Neale / 1932 Patterson Fork Road,Chicago,Illinois / 773-550-5107
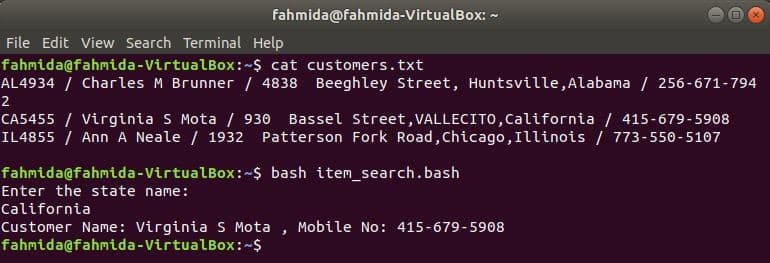
Create a bash file named item_search.bash with the following script. According to this script, the state value will be taken from the user and searched in the customers.txt file by grep command and passed to the awk command as input. Awk command will read 2nd and 4th fields of each line. If the input value matches with any state value of customers.txt file then it will print the customer’s name and mobile number, otherwise, it will print the message “No customer found”.
item_search.bash
echo "Enter the state name:"
read state
customers=`grep "$state" customers.txt | awk -F "/" ‘{print "Customer Name:" $2, ",
Mobile No:" $4}’`
if [ "$customers" != "" ]; then
echo $customers
else
echo "No customer found"
fi
Run the following commands to show the outputs.
$ bash item_search.bash
Output:
awk with sed
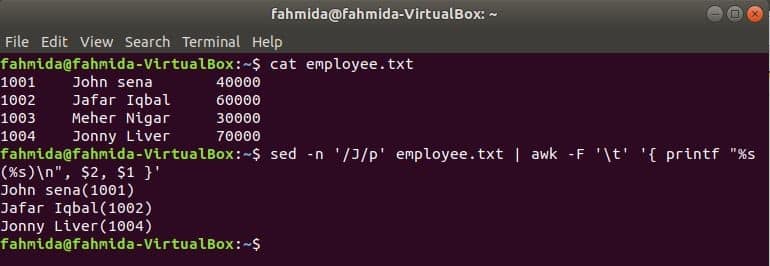
Another useful searching tool of Linux is sed. This command can be used for both searching and replacing text of any file. The following example shows the use of awk command with sed command. Here, sed command will search all employee names starts with ‘J’ and passes to awk command as input. awk will print employee name and ID after formatting.
$ sed -n ‘/J/p’ employee.txt | awk -F ‘t’ ‘{ printf "%s(%s)n", $2, $1 }’
Output:
Conclusion:
You can use awk command to create different types of reports based on any tabular or delimited data after filtering the data properly. Hope, you will be able to learn how awk command works after practicing the examples shown in this tutorial.






