In this lesson, we will see what is Apache Kafka and how does it work along with its some most common use-cases. Apache Kafka was originally developed at LinkedIn in 2010 and moved to become a top-level Apache project in 2012. It has three main components:
- Publisher-Subscriber: This component is responsible for managing and delivering data efficiently across the Kafka Nodes and consumer applications which scale a lot (like literally).
- Connect API: The Connect API is the most useful feature for Kafka and allows Kafka integration with many external data sources and data sinks.
- Kafka Streams: Using Kafka Streams, we can consider processing incoming data at scale in near real-time.
We will study a lot more Kafka concepts in coming sections. Let’s move ahead.
Apache Kafka Concepts
Before we dig deeper, we need to be thorough about some concepts in Apache Kafka. Here are the terms we should know, very briefly:
-
- Producer: This is an application which sends message to Kafka
- Consumer: This is an application which consumes data from Kafka
- Message: Data which is sent by Producer application to Consumer application through Kafka
- Connection: Kafka establishes TCP Connection between the Kafka cluster and the applications
- Topic: A Topic is a category to whom sent data is tagged and delivered to interested consumer applications
- Topic partition: As a single topic can get a lot of data at one go, to keep Kafka horizontally scalable, each topic is divided into partitions and each partition can live on any node machine of a cluster. Let us try to present it:
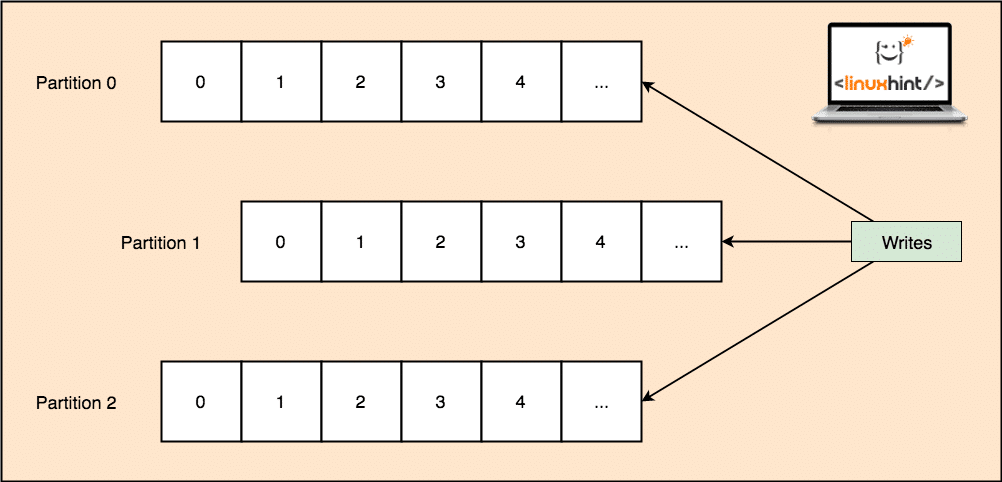
Topic Partitions
- Replicas: As we studied above that a topic is divided into partitions, each message record is replicated on multiple nodes of the cluster to maintain the order and data of each record in case one of the node dies.
- Consumer Groups: Multiple consumers who are interested in the same topic can be kept in a group which is termed as a Consumer Group
- Offset: Kafka is scalable as it is the consumers who actually store which message was fetched by them last as an ‘offset’ value. This means that for the same topic, Consumer A’s offset might have a value of 5 which means that it needs to process the sixth packet next and for the Consumer B, offset value could be 7 which means it needs to process eighth packet next. This completely removed the dependency on the topic itself for storing this meta-data related to each consumer.
- Node: A node is a single server machine in the Apache Kafka cluster.
- Cluster: A cluster is a group of nodes i.e., a group of servers.
The concept for Topic, Topic Partitions and offset can also be made clear with an illustrative figure:
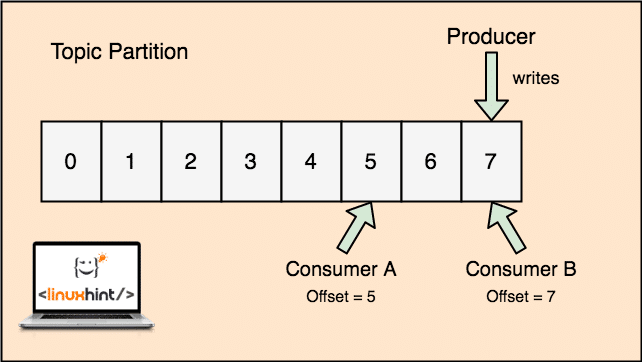
Topic partion and Consumer offset in Apache Kafka
Apache Kafka as Publish-subscribe messaging system
With Kafka, the Producer applications publish messages which arrives at a Kafka Node and not directly to a Consumer. From this Kafka Node, messages are consumed by the Consumer applications.
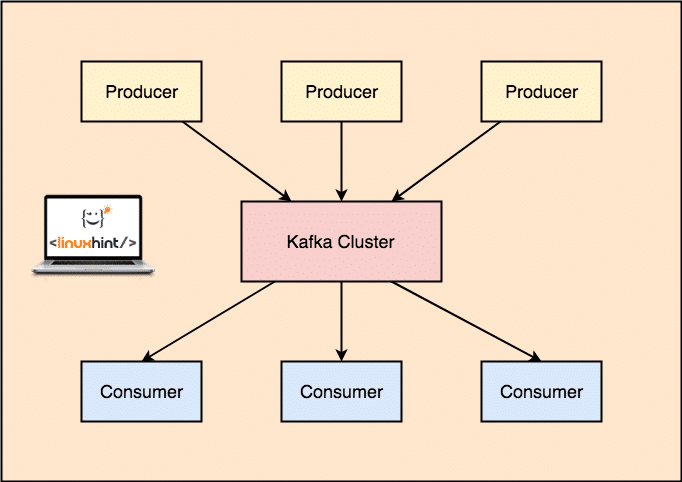
Kafka Producer and Consumer
As a single topic can get a lot of data at one go, to keep Kafka horizontally scalable, each topic is divided into partitions and each partition can live on any node machine of a cluster.
Again, Kafka Broker doesn’t keep records of which consumer has consumed how many packets of data. It is the consumers responsibility to keep track of data it has consumed. Due to the reason that Kafka doesn’t keep track of acknowledgements and messages of each consumer application, it can manage many more consumers with negligible impact on throughput. In production, many applications even follow a pattern of batch consumers, which means that a consumer consumes all the messages in a queue at a regular interval of time.
Installation
To start using Apache Kafka, it must be installed on the machine. To do this, read Install Apache Kafka on Ubuntu.
Use Case: Website Usage Tracking
Kafka is an excellent tool to be used when we need to track activity on a website. The tracking data includes and not limited to page views, searches, uploads or other actions users may take. When a user is on a website, the user might take any number of actions when he/she surfs through the website.
For example, when a new user registers on a website, the activity might be tracked on in what order does a new user explores the features of a website, if user sets their profile as needed or prefers to directly leap on to the features of the website. Whenever the user clicks a button, the metadata for that button is collected in a data packet and sent to the Kafka cluster from where the analytics service for the application can collect this data and produce useful insights on the related data. If we look to divide the tasks into steps, here is how the process will look like:
- A user registers on a website and enters into the dashboard. The user tries to access a feature straightaway by interacting with a button.
- The web application constructs a message with this metadata to a topic partition of topic “click”.
- The message is appended to the commit log and offset is incremented
- The consumer can now pull the message from the Kafka Broker and show website usage in real-time and show past data if it resets its offset to a possible past value
Use Case: Message Queue
Apache Kafka is an excellent tool which can act as a replacement for message broker tools like RabbitMQ. Asynchronous messaging helps in decoupling the applications and creates a highly scalable system.
Just like the concept of microservices, instead of building one large application, we can we can divide the application into multiple parts and each part has a very specific responsibility. This way, the different parts can be written in completely independent programming languages as well! Kafka has in-built partitioning, replication, and fault-tolerance system that makes it good as a large-scale message broker system.
Recently, Kafka is also seen as a very good log collection solution which can manage log file collection server broker and provide these files to a central system. With Kafka, it is possible to generate any event that you want any other part of your application to know about.
Using Kafka at LinkedIn
It is interesting to note that Apache Kafka was earlier seen and used as a way through which data pipelines could be made consistent and through which data was ingested into Hadoop. Kafka worked excellently when multiple data sources and destinations were present and providing a separate pipeline process for each combination of source and destination was not possible. LinkedIn’s Kafka architect, Jay Kreps describes this familiar problem well in a blog post:
My own involvement in this started around 2008 after we had shipped our key-value store. My next project was to try to get a working Hadoop setup going, and move some of our recommendation processes there. Having little experience in this area, we naturally budgeted a few weeks for getting data in and out, and the rest of our time for implementing fancy prediction algorithms. So began a long slog.
Apache Kafka and Flume
If you move out to compare these two on the basis of their functions, you’ll find a lot of common features. Here are some of them:
- It is recommended to use Kafka when you’ve multiple applications consuming the data instead of Flume, which is specially made to be integrated with Hadoop and can only be used to ingest data into HDFS and HBase. Flume is optimised for HDFS operations.
- With Kafka, it is a downside to have to code the producers and consumer applications whereas in Flume, it has many built-in sources and sinks. This means that if existing needs match with Flume features, you’re recommended to use Flume itself to save time.
- Flume can consume data-in-flight with the help of interceptors. It can be important for data masking and filtering whereas Kafka needs an external stream processing system.
- It is possible for Kafka to use Flume as a consumer when we need to ingest data to HDFS and HBase. This means that Kafka and Flume integrates really well.
- Kakfa and Flume can guarantee zero data loss with the correct configuration which is easy to achieve as well. Still, to point out, Flume doesn’t replicate events which means that if one of the Flume nodes fails, we will lose event access until the disk is recovered
Conclusion
In this lesson, we looked at many concepts about Apache Kafka. Read more Kafka based posts here.