To complete this lesson, you must have an active installation for Kafka on your machine. Read Install Apache Kafka on Ubuntu to know how to do this.
Installing Python client for Apache Kafka
Before we can start working with Apache Kafka in Python program, we need to install the Python client for Apache Kafka. This can be done using pip (Python package Index). Here is a command to achieve this:
This will be a quick installation on the terminal:
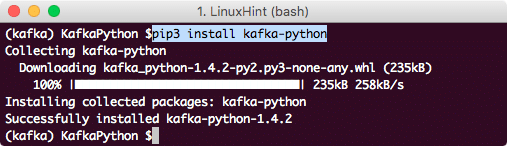
Python Kafka Client Installation using PIP
Now that we have an active installation for Apache Kafka and we have also installed the Python Kafka client, we’re ready to start coding.
Making a Producer
The first thing to have to publish messages on Kafka is a producer application which can send messages to topics in Kafka.
Note that Kafka producers are asynchronous message producers. This means that the operations done while a message is published on Kafka Topic partition are non-blocking. To keep things simple, we will write simple JSON publisher for this lesson.
To start, make an instance for the Kafka Producer:
import json
import pprint
producer = KafkaProducer(
bootstrap_servers=‘localhost:9092’,
value_serializer=lambda v: json.dumps(v).encode(‘utf-8’))
The bootstrap_servers attribute informs about the host & port for the Kafka server. The value_serializer attribute is just for the purpose of JSON serialization of JSON Values encountered.
To play with the Kafka Producer, let’s try printing the metrics related to the Producer and Kafka cluster:
pprint.pprint(metrics)
We will see the following out now:

Kafka Mterics
Now, let’s finally try sending some message to the Kafka Queue. A simple JSON Object will be a good example:
The linuxhint is the topic partition on which the JSON Object will be sent on. When you run the script, you won’t get any output as the message is just sent to the topic partition. It’s time to write a consumer so that we can test our application.
Making a Consumer
Now, we’re ready to make a new connection as a Consumer application and getting the messages from the Kafka Topic. Start with making a new instance for the Consumer:
from kafka import TopicPartition
print(‘Making connection.’)
consumer = KafkaConsumer(bootstrap_servers=‘localhost:9092’)
Now, assign a topic to this connection and a possible offset value as well.
consumer.assign([TopicPartition(‘linuxhint’, 2)])
Finally, we’re ready to print the mssage:
for message in consumer:
print("OFFSET: " + str(message[0])+ "t MSG: " + str(message))
Through this, we will get a list of all published messages on the Kafka Consumer Topic Partition. The output for this program will be:
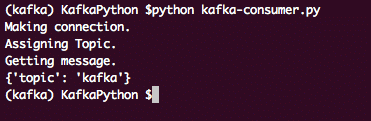
Kafka Consumer
Just for a quick reference, here is the complete Producer script:
import json
import pprint
producer = KafkaProducer(
bootstrap_servers=‘localhost:9092’,
value_serializer=lambda v: json.dumps(v).encode(‘utf-8’))
producer.send(‘linuxhint’, {‘topic’: ‘kafka’})
# metrics = producer.metrics()
# pprint.pprint(metrics)
And here is the complete Consumer program we used:
from kafka import TopicPartition
print(‘Making connection.’)
consumer = KafkaConsumer(bootstrap_servers=‘localhost:9092’)
print(‘Assigning Topic.’)
consumer.assign([TopicPartition(‘linuxhint’, 2)])
print(‘Getting message.’)
for message in consumer:
print("OFFSET: " + str(message[0])+ "t MSG: " + str(message))
Conclusion
In this lesson, we looked at how we can install and start using Apache Kafka in our Python programs. We showed how easy it is to perform simple tasks related to Kafka in Python with the demonstrated Kafka Client for Python.