Apache Spark is a data analytics tool that can be used to process data from HDFS, S3 or other data sources in memory. In this post, we will install Apache Spark on a Ubuntu 17.10 machine.
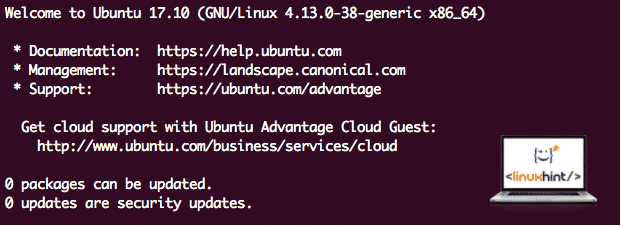
Ubuntu Version
For this guide, we will use Ubuntu version 17.10 (GNU/Linux 4.13.0-38-generic x86_64).
Apache Spark is a part of the Hadoop ecosystem for Big Data. Try Installing Apache Hadoop and make a sample application with it.
Updating existing packages
To start the installation for Spark, it is necessary that we update our machine with latest software packages available. We can do this with:
As Spark is based on Java, we need to install it on our machine. We can use any Java version above Java 6. Here, we will be using Java 8:
Downloading Spark files
All the necessary packages now exist on our machine. We’re ready to download the required Spark TAR files so that we can start setting them up and run a sample program with Spark as well.
In this guide, we will be installing Spark v2.3.0 available here:

Spark download page
Download the corresponding files with this command:
Depending upon the network speed, this can take up to a few minutes as the file is big in size:
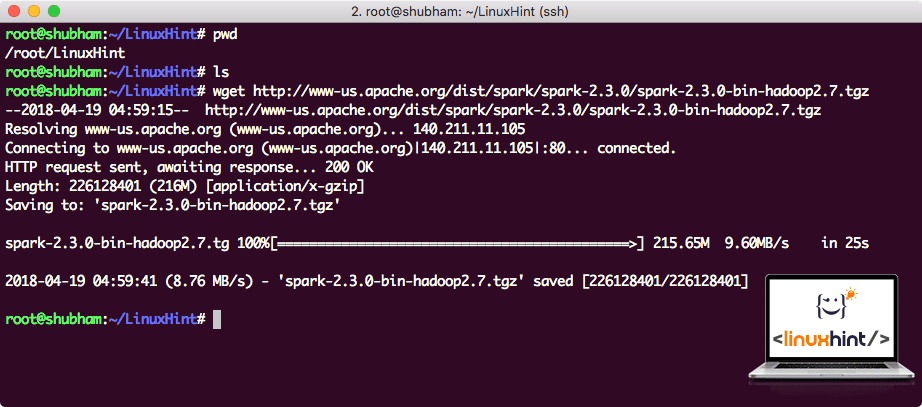
Downloading Apache Spark
Now that we have the TAR file downloaded, we can extract in the current directory:
This will take a few seconds to complete due to big file size of the archive:

Unarchived files in Spark
When it comes to upgrading Apache Spark in future, it can create problems due to Path updates. These issues can be avoided by creating a softlink to Spark. Run this command to make a softlink:
Adding Spark to Path
To execute Spark scripts, we will be adding it to the path now. To do this, open the bashrc file:
Add these lines to the end of the .bashrc file so that path can contain the Spark executable file path:
export PATH=$SPARK_HOME/bin:$PATH
Now, the file looks like:

Adding Spark to PATH
To activate these changes, run the following command for bashrc file:
Launching Spark Shell
Now when we are right outside the spark directory, run the following command to open apark shell:
We will see that Spark shell is openend now:

Launching Spark shell
We can see in the console that Spark has also opened a Web Console on port 404. Let’s give it a visit:

Apache Spark Web Console
Though we will be operating on console itself, web environment is an important place to look at when you execute heavy Spark Jobs so that you know what is happening in each Spark Job you execute.
Check the Spark shell version with a simple command:
We will get back something like:
Making a sample Spark Application with Scala
Now, we will make a sample Word Counter application with Apache Spark. To do this, first load a text file into Spark Context on Spark shell:
Data: org.apache.spark.rdd.RDD[String] = /root/LinuxHint/spark/README.md MapPartitionsRDD[1] at textFile at :24
scala>
Now, the text present in the file must be broken into tokens which Spark can manage:
tokens: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at :25
scala>
Now, initialise the count for each word to 1:
tokens_1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at :25
scala>
Finally, calculate the frequency of each word of the file:
Time to look at the output for the program. Collect the tokens and their respective counts:
res1: Array[(String, Int)] = Array((package,1), (For,3), (Programs,1), (processing.,1), (Because,1), (The,1), (page](http://spark.apache.org/documentation.html).,1), (cluster.,1), (its,1), ([run,1), (than,1), (APIs,1), (have,1), (Try,1), (computation,1), (through,1), (several,1), (This,2), (graph,1), (Hive,2), (storage,1), (["Specifying,1), (To,2), ("yarn",1), (Once,1), (["Useful,1), (prefer,1), (SparkPi,2), (engine,1), (version,1), (file,1), (documentation,,1), (processing,,1), (the,24), (are,1), (systems.,1), (params,1), (not,1), (different,1), (refer,2), (Interactive,2), (R,,1), (given.,1), (if,4), (build,4), (when,1), (be,2), (Tests,1), (Apache,1), (thread,1), (programs,,1), (including,4), (./bin/run-example,2), (Spark.,1), (package.,1), (1000).count(),1), (Versions,1), (HDFS,1), (D…
scala>
Excellent! We were able to run a simple Word Counter example using Scala programming language with a text file already present in the system.
Conclusion
In this lesson, we looked at how we can install and start using Apache Spark on Ubuntu 17.10 machine and run a sample application on it as well.
Read more Ubuntu based posts here.